2023 iThome 鐵人賽
分享至
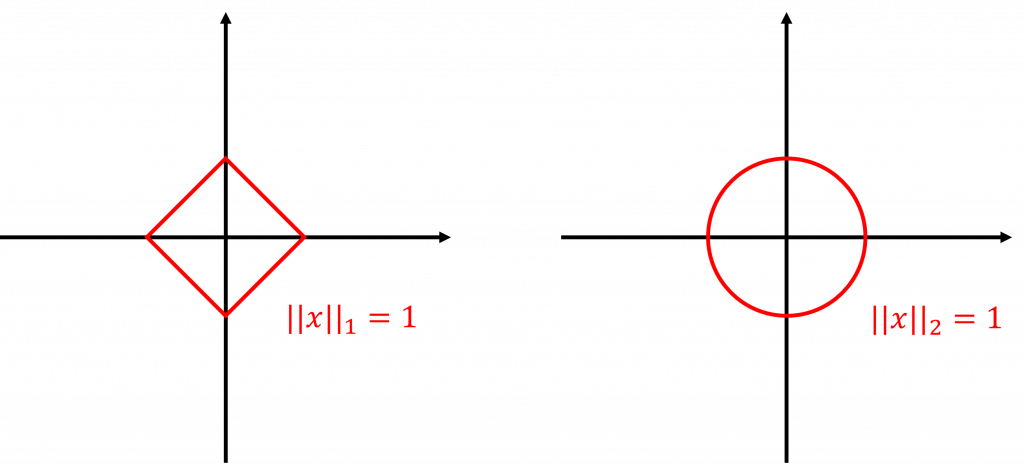
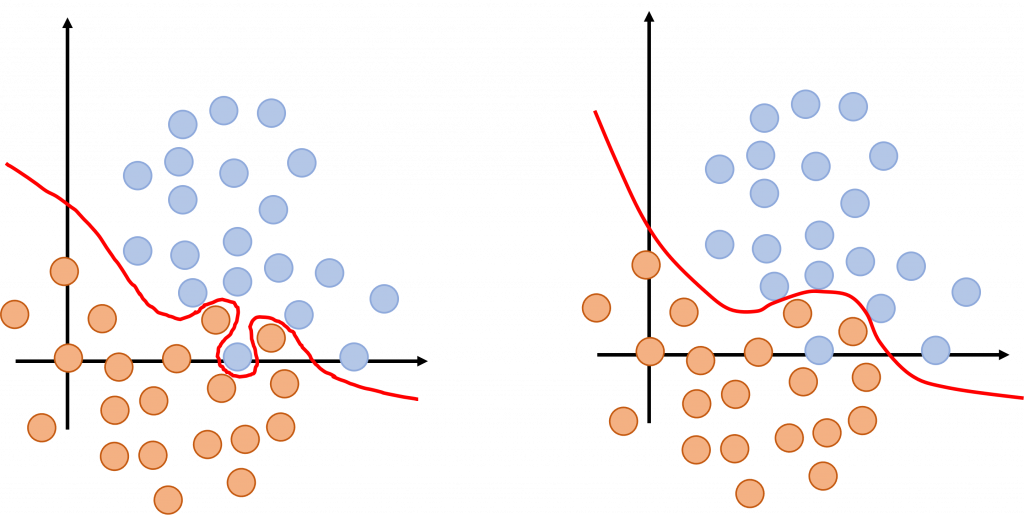
昨天的內容我們談到幾種常見的損失函數,分別被使用在不同的任務情境中。不過,我們是否只能使用這幾種損失函數呢?如果我的使用情境中有些特殊條件呢?我們是否有方法可以設計出一個客製化的模型訓練目標?
IT邦幫忙